ChatGPT 4.1 early benchmarks compared against Google Gemini
ChatGPT 4.1 is now rolling out, and it’s a significant leap from GPT 4o, but it fails to beat the benchmark set by Google Gemini.
Yesterday, OpenAI confirmed that developers with API access can try as many as three new models: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano.
According to the benchmarks, these models are far better than the existing GPT‑4o and GPT‑4o mini, particularly in coding.
For example, GPT‑4.1 scores 54.6% on SWE-bench Verified, which is better than GPT-4o by 21.4% and 26.6% over GPT‑4.5. We have similar results on other benchmarking tools shared by OpenAI, but how does it compete against Gemini models.
ChatGPT 4.1 early benchmarks
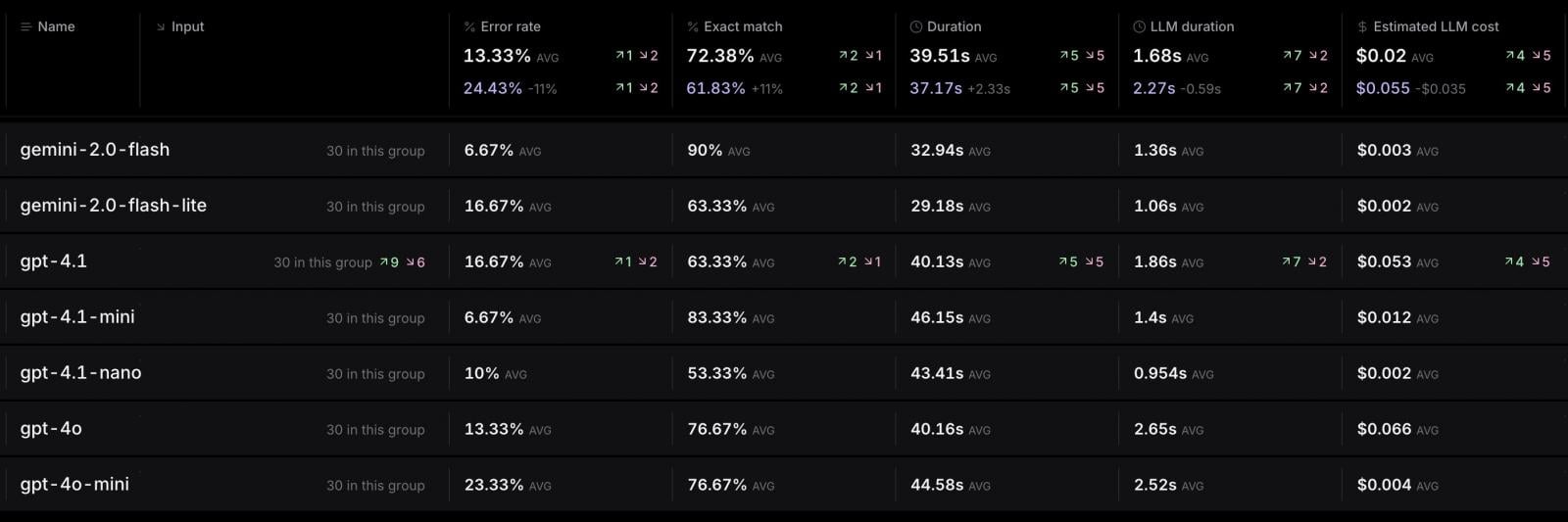
According to benchmarks shared by Stagehand, which is a production-ready browser automation framework, Gemini 2.0 Flash has the lowest error rate (6.67%) along with the highest exact‑match score (90%), and it’s also cheap and fast.
On the other hand, GPT‑4.1 has a higher error rate (16.67%) and costs over 10 times more than Gemini 2.0 Flash.
Other GPT variants (like “nano” or “mini”) are cheaper or faster but not as accurate as GPT-4.1
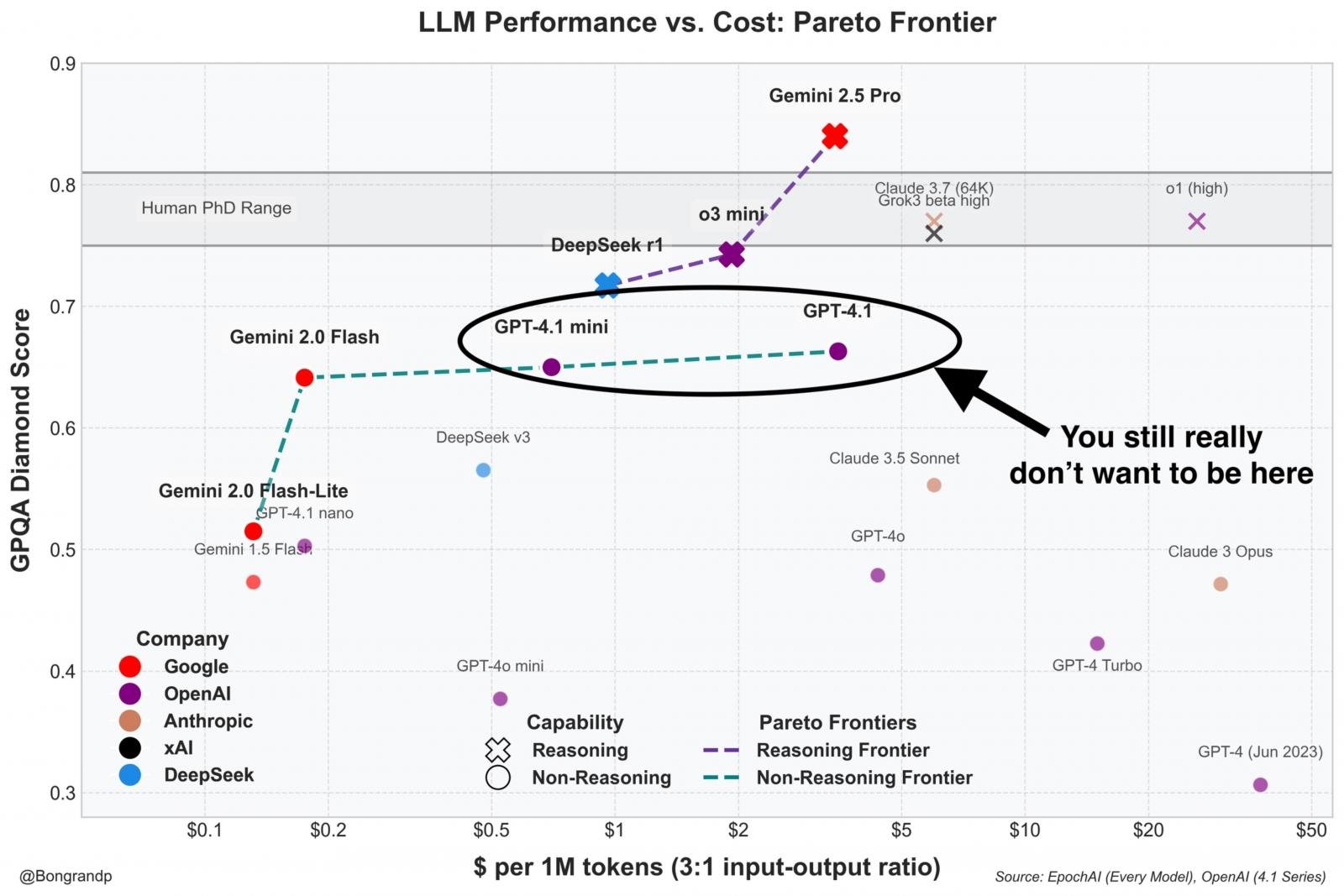
In another data shared by Pierre Bongrand, who is a scientist working on RNA at Harward, GPT‑4.1 offers poorer cost-effectiveness than competing models.
This is an important factor because GPT4.1 is cheaper than ChatGPT 4o.
Models like Gemini 2.0 Flash, Gemini 2.5 Pro, and even DeepSeek or o3 mini lie closer to or on the frontier, which suggests they deliver higher performance at a lower or comparable cost.
Ultimately, while GPT‑4.1 still works as an option, it’s clearly overshadowed by cheaper or more capable alternatives.
Coding benchmarks show GPT-4.1 lags behind Gemini 2.5
.jpg)
We’re seeing similar results in coding benchmarks, with Aider Polyglot listing GPT-4.1 with a 52% score, while Gemini 2.5 is miles ahead at 73%.
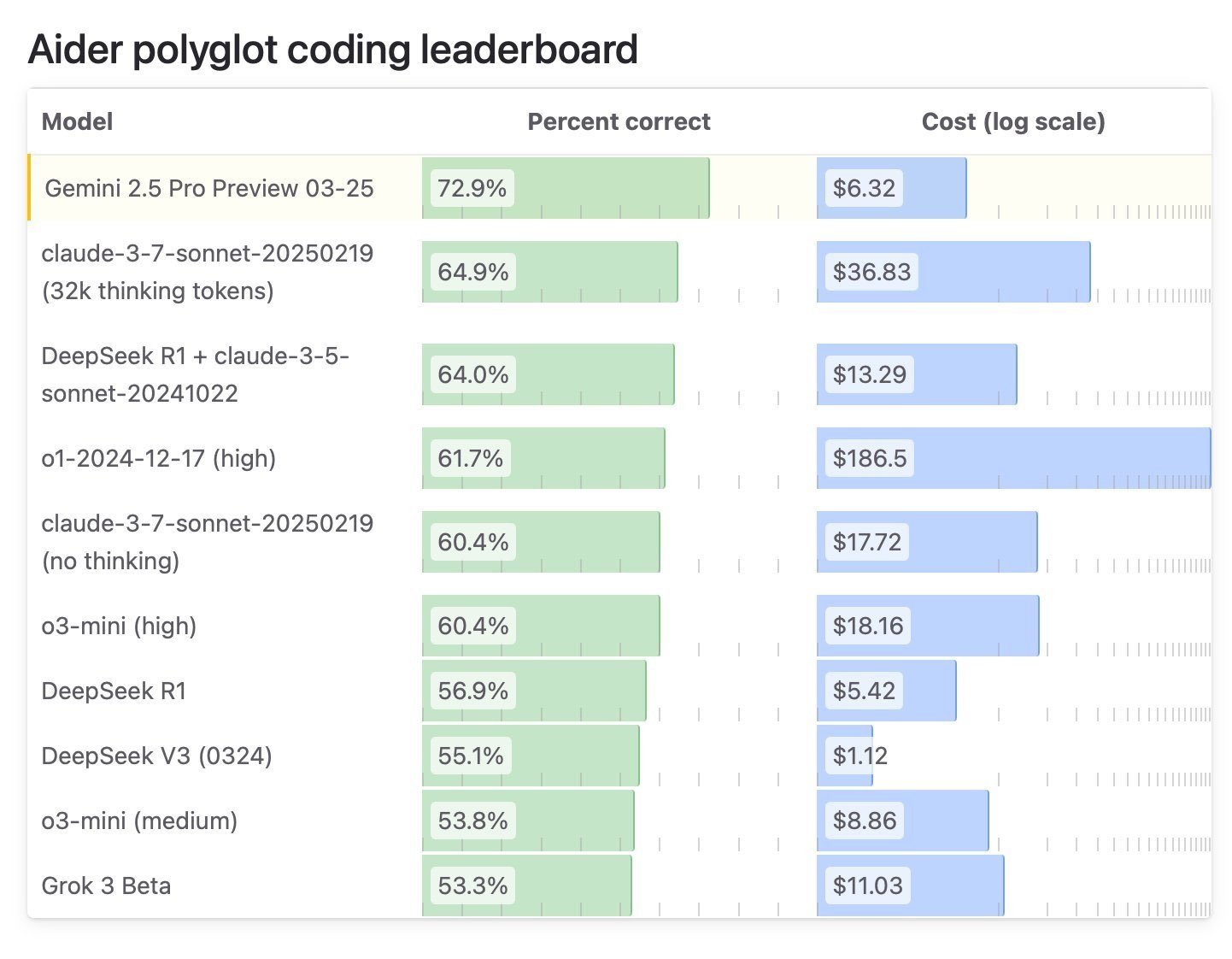
It is also important to note that GPT-4.1 is a non-reasoning model, and it’s still one of the best models for coding.
GPT-4.1 is available via API, but you can use it for free if you sign up for Windsurf AI.
Source link
